One of the most wonderful aspects about IGT is that it came with challenges unlike anything I had ever seen — and I’ve faced aplenty over the years. One day my team leader asked me for some assistance on ROW_NUMBER since I had a good amount of experience with it. It turned out that his needs were too complex to solve with ranking functions, so he went with a cursor (which was perfectly justified).
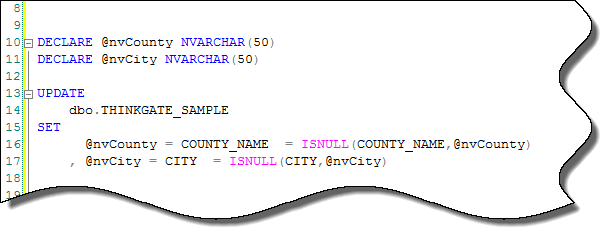
Still, I was curious to see if I could come up with a set-based approach (mostly because I hated to let him down on the wonders that can be worked with ranking). So over the weekend in my hotel room I thought through the specs again and came across the little-known (or little-used) gem you see highlighted in the syntax below.
Note: This update is colloquially called a “quirky update”

I whipped up a procedure using the “@variable = column = expression” syntax and sent my colleague an email so he’d be all set on Monday morning. When he got back to me a couple of days later he thanked me for my efforts, but said that he had already developed a cursor that does the same thing — or so he thought.
I walked over to his desk and said, “It’s not a loop” — and he was stunned to discover what he found when he took another look. The illusion of a loop was that the logic was all there — complete with variables and layers of case statements, and yet it was a set-based update. Just for a moment he thought he had a snag when he remembered that he had to do 2 cursors (one of which was in reverse order).
My solution covered that too — I suggested that he just throw his data into a #temp table, create a clustered index in descending order, run the update, and replace the data.
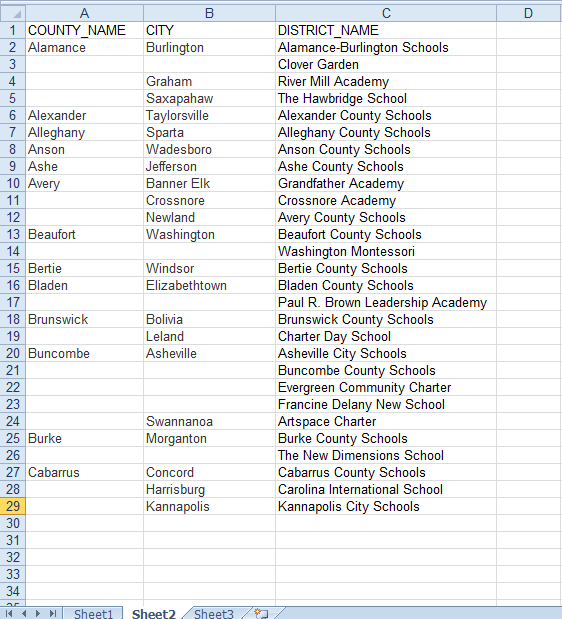
My team leader was thrilled — as was I, for not only did I deliver on helping him out, but I also knew how I was going to apply this solution elsewhere. Without going into detail, the bottom line is that I was faced with several source files that were structured more like reports (an extremely simplified replica of which you can see below).
This screenshot is a cakewalk compared to what I had, because the patterns are clear-cut. Nevertheless, the principles are the same.
Note: The following data is public information that I used to create a sample that would be universally understood.
What I originally did for these files was nothing earth-shattering though — I identified all possible patterns for each file and went with a cursor. Given the small amount of data involved, it would have been fine had I left the cursors alone — but I replaced them all with the “quirky update” approach. We weren’t in production yet anyway, and since the logic was all in place — it was simple to swap them out.
To give you an idea of the difference in performance when it really would matter though — I created a sample file of North Carolina school districts, and then removed all the duplicate entries (up to 28 rows) in order to illustrate the fundamental issue I was facing at IGT. Then I duplicated that data 20,000 times so I could have over a half million records.
I wrote a 70-line cursor that took 17 seconds to complete the update.
The snippet you see in the screenshot below updated the same number of rows in 1 second.